
亲爱的网友们,今天我们要探讨一个科技领域的热门话题——如何通过缓存保持大模型性能,并深入了解大模型金字塔式信息汇聚模式的奥秘。这不仅是一场技术的盛宴,更是一次思维的碰撞。让我们一起走进这个充满智慧的世界,揭开大模型的神秘面纱。
让我们来了解一下什么是“大模型”。在人工智能领域,大模型通常指的是那些拥有数十亿甚至数百亿参数的深度学习模型。这些模型在处理复杂任务时表现出色,但同时也带来了巨大的计算和存储挑战。为了确保这些大模型在实际应用中能够高效运行,缓存技术成为了关键。
缓存,这个在计算机科学中并不陌生的概念,在这里扮演着至关重要的角色。通过合理设计缓存策略,可以显著减少大模型在处理数据时的延迟,提高响应速度,从而保持其高性能。这就像是在大模型的计算之路上铺设了一条快速通道,让数据能够更加顺畅地流动。
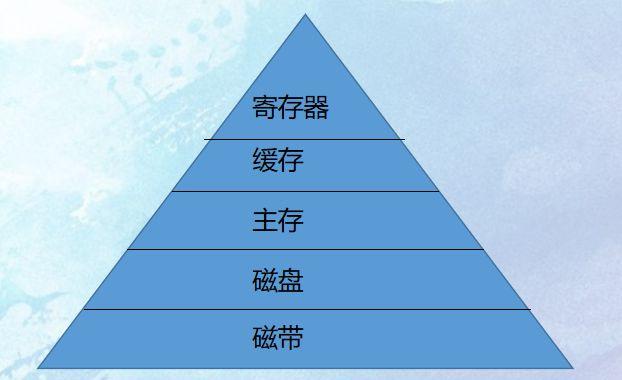
我们要探讨的是大模型的金字塔式信息汇聚模式。这种模式可以形象地理解为一座金字塔,底层是海量的原始数据,层级的上升,数据逐渐被提炼和整合,最终在顶层形成高度浓缩和精炼的信息。这种自下而上的信息汇聚方式,不仅提高了信息的处理效率,增强了信息的准确性和可靠性。
在这个金字塔中,每一层都承担着不同的角色和功能。底层的数据采集层负责收集各种原始数据,这些数据可能来自不同的来源和渠道。中层的数据处理层则负责对这些数据进行清洗、分类和整合,为上层的决策支持层提供坚实的基础。顶层的决策支持层则利用这些经过提炼的信息,为各种应用场景提供智能化的决策支持。
这种金字塔式的信息汇聚模式,不仅适用于大模型,也可以广泛应用于各种信息处理和决策支持系统中。它通过层级化的结构设计,实现了信息的高效汇聚和利用,为我们的工作和生活带来了极大的便利。
总结一下,通过缓存技术保持大模型性能,以及探索大模型的金字塔式信息汇聚模式,我们不仅能够更好地理解大模型的运作机制,能够为未来的技术发展提供新的思路和方向。这不仅是一次技术的探索,更是一次智慧的启迪。
我想用一句话来结束今天的分享:“在科技的海洋中,每一次探索都是对未知的挑战,每一次创新都是对未来的承诺。”,大模型技术在未来的发展中,能够带给我们更多的惊喜和突破!
缓存保持大模型性能 大模型金字塔式信息汇聚模式探秘 人工智能 深度学习 科技探索
感谢大家的阅读,希望今天的分享能够给大家带来一些启发和思考。如果你对大模型技术感兴趣,欢迎在评论区留言讨论,我们一起交流学习,共同进步!









昊玺
这家伙太懒。。。
- 暂无未发布任何投稿。


