
张钹直指人工智能行业当前问题:没有理论只有模型算法
8月1日,张钹直指人工智能行业当前问题:没有理论只有模型算法中国科学院院士、清华大学人工智能研究院名誉院长张钹在ISC.AI2024第十二届互联网安全大会的演讲上表示,当前人工智能还没有理论,只有发展出来针对的模型和算法,它们都是针对特定领域的,软件或硬件也都是专用的,市场很小,因此到现在为止还没有发展出一个大型的人工智能产业,问题就出在这里。
张钹现年已经89岁高龄,过去几十年里,他在清华大学培养了一批人工智能人才,是中国人工智能学科的奠基人之一。当前不少火热的“清华系”大模型企业如生数科技、智谱AI、面壁智能、Kimi等,均受益于在清华打下的技术基础,核心技术人才或直接或间接师承于张钹。
本次演讲,张钹不仅指出了当前人工智能技术存在的缺陷和问题,也给出了未来改进的方向。
张钹演讲时现场观众拍摄其演讲PPT新京报贝壳财经记者罗亦丹/摄
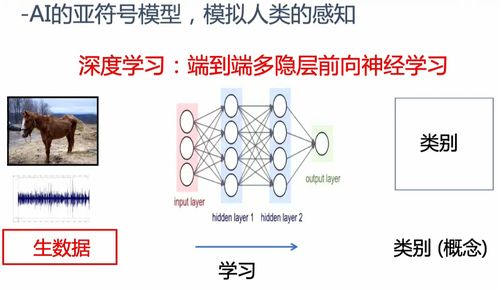
当考虑基础模型时,要考虑3大能力与1大缺陷
在张钹看来,因为理论的限制,人工智能产业的前一阶段必须要结合具体的应用领域来发展,因此这一阶段发展出的人工智能属于专用人工智能,即“弱”人工智能。不过,他也指出,目前基础模型在语言问题上做到了通用,“我们考虑基础模型的时候需要考虑3大能力与1大缺陷,这点是非常重要,是我们考虑今后产业发展的出发点。”
他解释称,大语言模型的强大之处体现在强大的语言生成能力、强大的人机自然交互能力和强大的举一反三能力,“大语言模型的语言生成属于开放领域,能够生成多样化的结果,所有输出人类都可以理解,即便是‘胡说八道’我们也可以理解在胡说什么,这一点非常重要。人类跟机器在开放领域进行自然语言对话,我们之前以为要通过几代人的努力才能达到这个目标,但大家没想到的是2020年这个目标已经达到了。”
张钹表示,大模型的缺陷就是“幻觉”,“因为我们要求它有多样性的输出,必然它会产生错误。这个错误跟机器都会产生错误非常不一样,机器产生的错误往往是我们可以控制的,这个错误是本身的错误,是一定会发生的,而且我们不可控,所以,这点也是我们后面考虑它应用需要考虑的问题。”
结合3大能力与1大缺陷,张钹总结出了大模型当前适合应用的场景:对错误的容忍程度要高。他表示从产业情况来看,大模型的应用呈现“U”字形——前部的规划、设计要求内容多样性,后部的服务、推荐也要求多样性,同时对错误的容忍程度较高,但中间部分就需要根据情况来考虑使用。
尽管存在问题,张钹还是表示不论怎样“模型是一定要用的”,“因为有了模型底座以后,应用的效率和质量一定会提高。过去的应用场景我们是在空的计算机上开发软件提供服务,空的计算机相当于文盲,而现在有了大模型,平台至少是个高中生,开发效率一定会提高,以后的方向一定是这样。”
张钹重点分析了幻觉出现的根本原因,他认为模型的根本限制在于目前所有的机器所做的工作都是外部驱动,人类教它怎么做,而不是自己主动做。同时,它生成的结果受提示词的影响非常大,与人类是在内部意图的控制下完成工作有明显的区别。
大模型未来的4个发展方向:对齐、多模态、智能体、具身智能
张钹介绍,未来大模型有4个发展方向,对如何改进大模型非常重要。
其一是与人类对齐,“大模型没有判断对错的能力,自己不能自我更新,都是人类驱动下去更新的,不突破这一点,机器就不能自我进化。大模型需要外部的提示,所以在人类的驱动下改正大模型的错误是我们做的第一件工作。”
其二是多模态生成,“多模态生成将来对产业的发展非常重要,因为大家看到大模型主要是生成文本,但是我们用同样的办法生成图像、声音、视频、代码之后,生成的水平是跟人类的水平接近的。我们现在为什么图像能生成的那么好,主要是把图像跟文本挂钩。所以,最本质的是文本处理的突破。”
其三是AIAgent(智能体)的概念,“要把大模型和周围的虚拟环境结合起来,让环境提示它的错误,因为一件事做了之后才知道对和错,因此智能体的概念非常重要,让环境提示智能体,让它有反思的机会,去改正错误。”
其四是具身智能,“通过加上机器人,让大模型在物理世界也能够工作。将来如何发展通用机器人?我认为要‘软件通用,硬件多样化’,马斯克宣传人形机器人,但我认为将来不止限于人形机器人。”
在张钹看来,发展第三代人工智能,首先必须建立理论,大模型的存在没有理论可以解释,所以才会引起各种困惑和误解,机器发展规模越来越大,理论不能解释就会引起恐慌,得到安全、可控、可信、可靠、可扩展的人工智能技术,在这一领域没有发展完善之前,人工智能始终是存在安全问题的。
新京报贝壳财经记者罗亦丹
编辑岳彩周
校对柳宝庆









绍邦
这家伙太懒。。。
- 暂无未发布任何投稿。


